Two ways of Snowflake Auto Ingestion Process
Snowflake is cloud-based data platform. This platform is very efficient to handle large datasets.
In general, for regular usage, we use either MySQL, PostgreSQL and other similar RDBMS or No SQL databases or graph databases. But if we are generating too much data and as your regular Databases can not handle some scenarios like analytics, reporting or machine learning workflows we need the tool which can handle those use cases and Snowflake is one of the best.
We are generating data in RDBMS and we have to pull them into Snowflake so we have few options available.
- Custom pipeline — We will talk about this one in this.
- Third party ETL tools
- Snowflake auto ingestion process — We will talk about this as well.
- RDBMS connector in snowflake — (Still in development)
Custom Workflow
We can use snowflake stage, pipe and task to write data into snowflake. Before setting up those resources, I would suggest you pull your data into AWS Simple Storage (S3) or Azure Blob Storage. To write data to S3 you can create your own workflow with your convenience technologies.
One way to do is that, you can write lambda which runs periodically or you can write any cron based script which should have access to both S3 and your RDBMS database and process would be read data from S3 with some timestamps and write into S3 path with any format you like csv, json, parquet, etc.
Once above process is established, you will have files coming regularly in S3 now, we need our pipeline to write data to snowflake from cloud storage.
What do you expect with this ingestion pipeline?
Whenever any new file lands in cloud storage(AWS, Azure), our so called pipeline should trigger and write data into raw table. Following two paths to build that pipeline
- Use snowflake stage, pipes, streams, tasks, procedures to build datasets in snowflake (Snowflake auto ingestion process)
- Use same resources but with AWS lambda or Azure functions you can avoid tasks and pipes (Custom Pipeline)
=> Snowflake auto ingestion process — Pipeline using all snowflake resources
Auto ingestion with snowflake pipe is a serverless process on the Snowflake side that does not require a virtual warehouse or any manual intervention
Pricing explained here — https://www.cloudzero.com/blog/snowflake-pricing
Auto ingestion with snowflake pipe can handle files of any size and frequency, as long as they are compatible with the S3 event notification system
Auto ingestion with snowflake pipe can achieve near real-time latency for data ingestion, depending on the file size and frequency. Though we have observed 30 seconds delay in many cases.
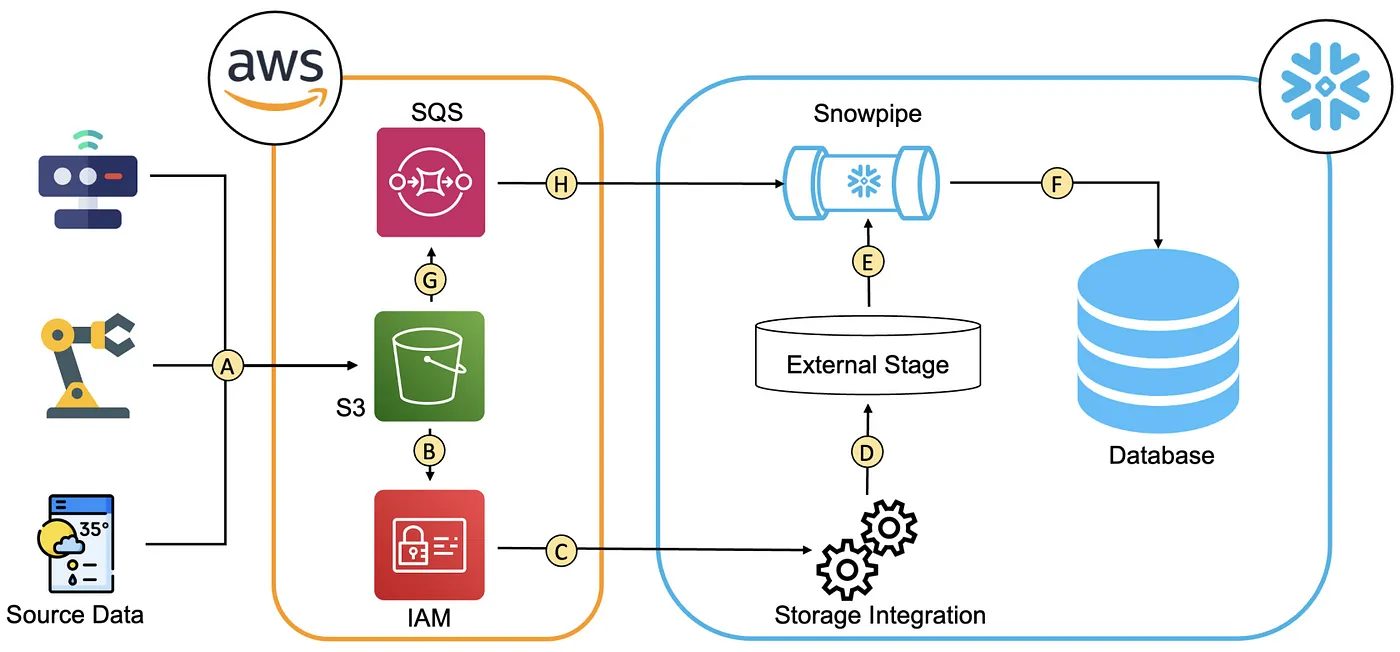
Following steps will be involved for auto ingestion process in this pipeline
- Create storage integration
- Create stage using above storage integration
- Create RAW table where data will be store in JSON format
- Create stream on top of RAW table to capture changes
- Create Processed table where data will be stored after transformation
- Create auto notification from cloud provider side. Ex. S3 auto notification.
- Use ARN of that notification to setup snow pipe which includes COPY command.
- Create transformation or flattening procedure
- Create Task which will run periodically to transform or flatten the data and store in processed table
If you will follow all the steps, your pipeline will be ready for your workflow.
Costing for first approach
If you will build pipeline using first approach then following parameters will be involved in costing of while pipeline
- pipe overhead costing per file(fixed cost per file)
- pipe COPY command compute cost (Serverless)
- task execution compute cost (Warehouse compute cost)
=> Custom pipeline — Another way of building pipeline using external cloud function
Using lambda to connect Snowflake and run copy statement from there requires managing your own lambda function, which adds complexity and maintenance overhead to your data pipeline
This pipeline requires a virtual warehouse to perform the copy operation, which adds cost to your Snowflake account
Running copy statement from lambda may achieve the same latency as auto ingestion with snowflake pipe or even better to get it real time, depending on the frequency and configuration of your lambda function.
In this case, you also need to setup few resources so please follow below steps in order.
- Create storage integration
- Create stage using above storage integration
- Create RAW table where data will be store in JSON format
- Create stream on top of RAW table to capture changes
- Create Processed table where data will be stored after transformation
- Create auto notification from cloud provider side. Ex. S3 auto notification.
- Create transformation or flattening procedure
- Create lambda or azure function which will be triggered by above auto notification. This lambda will hit two following commands
-- Query to copy data from file to raw table
COPY into <table_name> from @external_stage/<path of the s3 file>
-- Procedure will transform the data listening from stream and write into processed
CALL <flattening procedure>;Costing for second approach
If you will build pipeline using second approach then following parameters will be involved in costing of while pipeline
- lambda invocation and execution cost
- COPY and CALL procedure compute cost (Warehouse compute cost)
Cost Comparison
As snowflake doesn’t provide details costing on snowflake pipe side it’s tough to do comparison but I have done some rough calculation so you can just consider it with some caution or you also would like to calculate by yourself using this as a reference.
The exact costs will depend on your specific data volume, frequency, latency, and pricing plans.
Example — let’s assume that you have 10k of data files in S3 that you want to ingest into Snowflake every day. Let’s also assume that you use the EU West region for AWS and EU west for Snowflake. Based on the current pricing plans , we can estimate the costs as following:
(Not included procedure cost as it is common in both)
First Approach
Cost of Snowpipe credits = $0.06 per credit * 1 credit per hour * 24 hours * 30 days = $43.2 per month
Cost of Snowpipe overhead = $0.06 per credit * 0.0005 credits per file * 10000 files * 30 days = $9 per month
- Total Cost = Cost of Snowpipe credits + Cost of Snowpipe overhead
- Calculated Cost = $43.2 + $9 = $52.2 per month
Second Approach
Cost of lambda invocation = $0.2 per million requests * 10K requests * 30 days / 1000000 requests = $0.06 per month
Cost of lambda execution = $0.00001667 per GB-second * 128 MB memory * 20 seconds average duration * 10K requests * 30 days / 1024 MB = $1.24 per month
Cost of virtual warehouse credits = $2 per credit * 1 credit per hour * 24 hour average usage * 30 days = $60 per month
Total Cost = Cost of lambda invocation + Cost of lambda execution + Cost of virtual warehouse credits
Calculated Cost = $0.06 + $0.62 + $60 = $60.68 per month
As you can see, using S3 file to Snowflake auto ingestion is cheaper than using lambda to connect Snowflake and run copy statement by about $16.7 per month in this example. However, this is just an estimate based on some assumptions and may not reflect your actual costs or performance. You may want to do your own calculations based on your specific data volume, frequency, latency, and pricing plans.
Conclusion
I have tried implementing both ways and works fine so there are some trade off between these two and both have their own benefits over each other. So based your needs you can implement suitable approach.
I hope this article helped you to understand auto ingetsion process. To implement in real syntaxes and other stuff you can find in official documentation.
Another Costing Ref — https://www.snowflake.com/legal-files/CreditConsumptionTable.pdf